基础配置
首先,我们向 deno.json 中添加 langchain 相关的依赖别名,为了保证大家正常学习教程,我们会锁定版本:
json复制代码{
"imports": {
"lodash": "npm:/lodash@4.17.21",
"dotenv": "https://deno.land/std@0.220.0/dotenv/mod.ts",
"langchain": "npm:/langchain@0.1.28",
"langchain/": "npm:/langchain@0.1.28/",
"@langchain/openai": "npm:/@langchain/openai@0.0.22",
"@langchain/openai/": "npm:/@langchain/openai@0.0.22/",
"@langchain/core": "npm:/@langchain/core@0.1.48",
"@langchain/core/": "npm:/@langchain/core@0.1.48/"
},
"deno.enable": true
}
这里我们除了添加正常的langchain 包之外,我们还添加了langchain/ 来方便引用 langchain 中众多的子包,其他的依赖也是类似的逻辑。
然后,我们就可以引入环境变量,主要是相关的 keys。这里我们再次强调,一定不能将 env 文件上传到 github 或者任意公开渠道!!!
js复制代码import { load } from "dotenv";
const env = await load();
const process = {
env
}
什么是 LCEL
如果你之前看到 langchain.js 其他的相关教程,可能写法并不是 LCEL。 LCEL(LangChain Expression Language) 是 langchain 无论是 python 还是 js 版本都在主推的新设计。
站在当前这个时间点,我认为应该全面转向 LCEL,可以抛弃之前的旧写法,为了防止混淆,本教程所有代码都会基于 LCEL,也并不会介绍旧的 langchain 写法。
那 LCEL 有什么优势呢? LCEL 从底层设计的目标就是支持 从原型到生产 完整流程不需要修改任何代码,也就是我们在写的任何原型代码不需要太多的改变就能支持生产级别的各种特性(比如并行、steaming 等),具体来说会有这些优势:
- 并行,只要是整个 chain 中有可以并行的步骤就会自动的并行,来减少使用时的延迟。
- 自动的重试和 fallback。大部分 chain 的组成部分都有自动的重试(比如因为网络原因的失败)和回退机制,来解决很多请求的出错问题。 而不需要我们去写代码 cover 这些问题。
- 对 chain 中间结果的访问,在旧的写法中很难访问中间的结果,而 LCEL 中可以方便的通过访问中间结果来进行调试和记录。
- LCEL 会自动支持 LangSimith 进行可视化和记录。这是 langchain 官方推出的记录工具,可以记录一条 chian 运行过程中的大部分信息,来方便调试 LLM 找到是哪些中间环节的导致了最终结果较差。这部分我们会在后续的章节中涉及到。
一条 Chain 组成的每个模块都是继承自 Runnable 这个接口,而一条 Chain 也是继承自这个接口,所以一条 Chain 也可以很自然的成为另一个 Chain 的一个模块。并且所有 Runnable 都有相同的调用方式。 所以在我们写 Chain 的时候就可以自由组合多个 Runnable 的模块来形成复杂的 Chain。
对于任意 Runnable 对象,其都会有这几个常用的标准的调用接口:
invoke基础的调用,并传入参数batch批量调用,输入一组参数stream调用,并以 stream 流的方式返回数据streamLog除了像 stream 流一样返回数据,并会返回中间的运行结果
Talk is cheap,让我们来看 code 演示,其中会涉及到很多 Langchain 中陌生的概念,大家可以简单从它的表现中理解,我们会在后续的章节中深入介绍。
invoke
首先,我们用最基础的 ChatOpenAI,这显然是一个 Runnable 对象,我们以此为例来让大家熟悉 LCEL 中 Runnable 中常见的调用接口。 其中 HumanMessage 你可以理解成构建一个用户输入,各种 Message 的介绍我们会在后续章节中展开介绍。 注意这里 chatModel 需要的输入是一个 Message 的列表。
import { ChatOpenAI } from "@langchain/openai";
import { HumanMessage } from "@langchain/core/messages";
const model = new ChatOpenAI({
configuration: {
baseURL: "https://oneapi.yourapi.net/v1"
}
});
await model.invoke([
new HumanMessage("Tell me a joke")
])
这里,我们就完成了一个基础的对 Runnable 接口的调用,我们会拿到其对应的输出
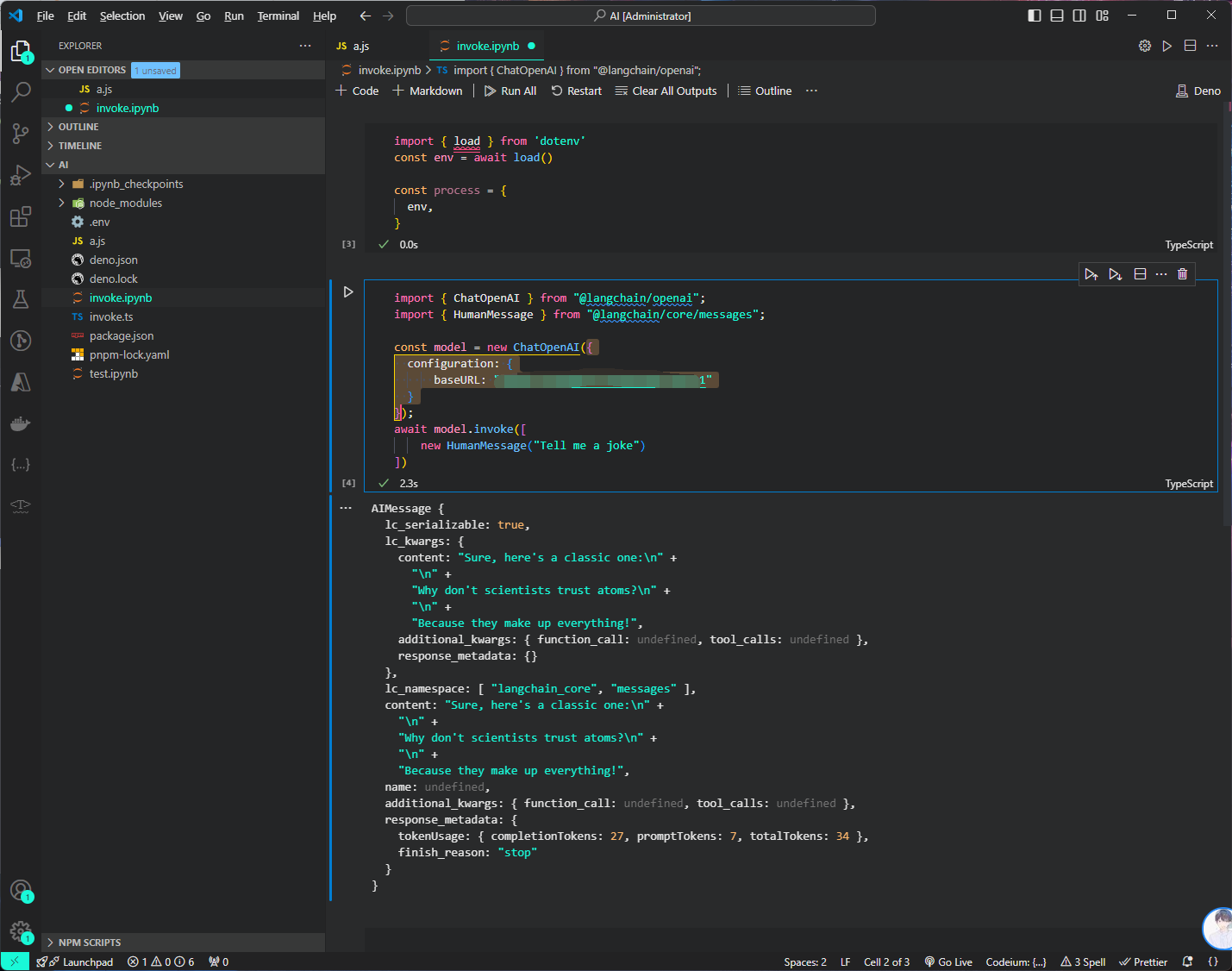
AIMessage {
lc_serializable: true,
lc_kwargs: {
content: "Sure, here's a classic one:\n" +
"\n" +
"Why don't scientists trust atoms?\n" +
"\n" +
"Because they make up everything!",
additional_kwargs: { function_call: undefined, tool_calls: undefined },
response_metadata: {}
},
lc_namespace: [ "langchain_core", "messages" ],
content: "Sure, here's a classic one:\n" +
"\n" +
"Why don't scientists trust atoms?\n" +
"\n" +
"Because they make up everything!",
name: undefined,
additional_kwargs: { function_call: undefined, tool_calls: undefined },
response_metadata: {
tokenUsage: { completionTokens: 27, promptTokens: 7, totalTokens: 34 },
finish_reason: "stop"
}
}
为了方便展示,我们会加入一个简单的 StringOutputParser 来处理输出,你可以简单的理解为将 OpenAI 返回的复杂对象提取出最核心的字符串,组成一个最基础的 Chain 来演示, Runnable 中各个调用方式
import { ChatOpenAI } from "@langchain/openai";
import { HumanMessage } from "@langchain/core/messages";
import { StringOutputParser } from "@langchain/core/output_parsers";
const chatModel = new ChatOpenAI({
configuration: {
baseURL: "https://oneapi.yourapi.net/v1"
}
});
const outputPrase = new StringOutputParser();
const simpleChain = chatModel.pipe(outputPrase)
await simpleChain.invoke([
new HumanMessage("Tell me a joke")
])
因为我们添加了 OutputParser,所以输出就是一个普通的文本,而不是 OpenAI 返回复杂的对象。
输出结果如下
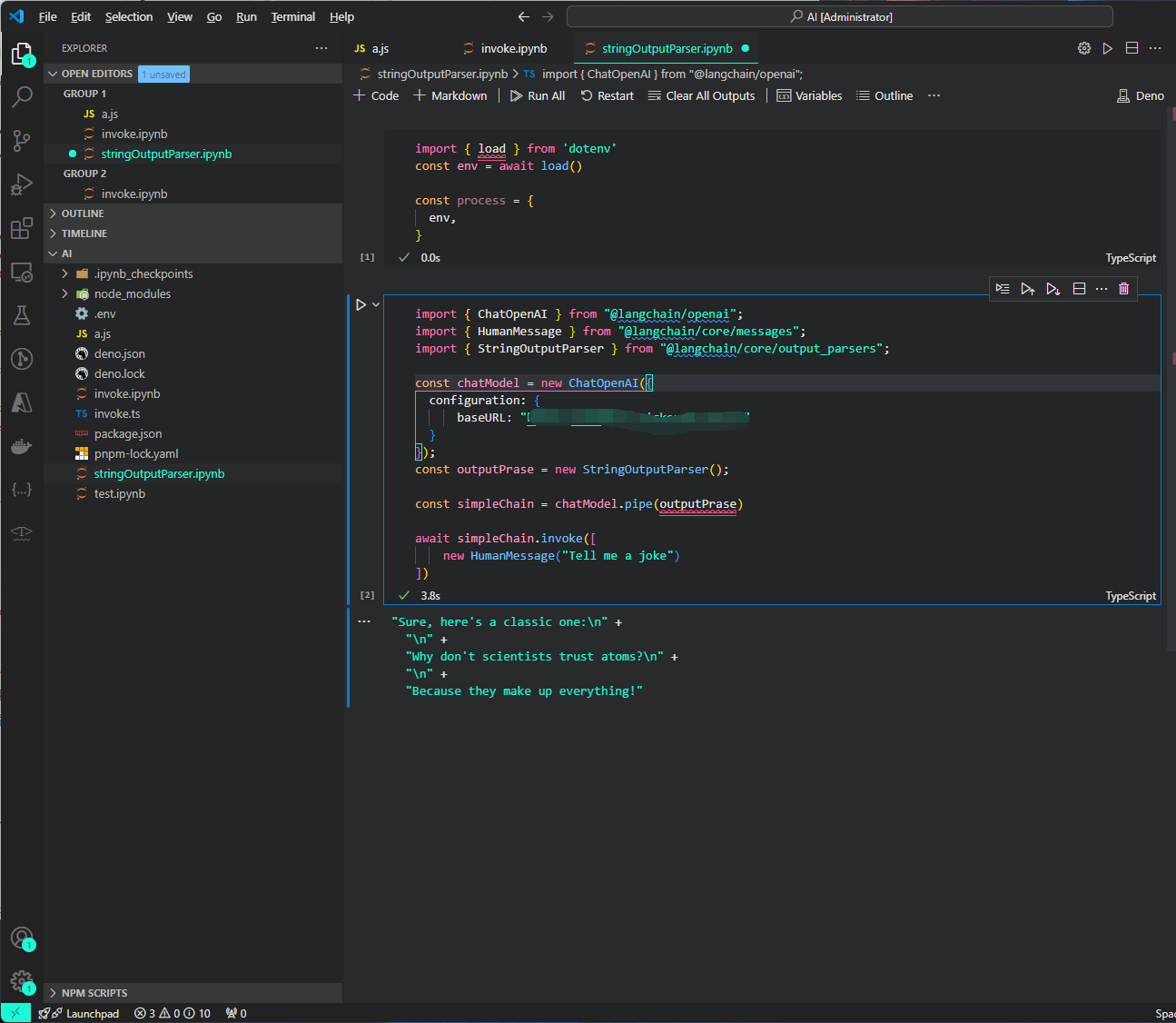
在 LCEL 中,使用 .pipe() 方法来组装多个 Runnable 对象形成完整的 Chain,可以看到我们是用对单个模块同样的 invoke 方法去调用整个 chain。 因为无论是单个模块还是由模块组装而成的多个 chain 都是 Runnable。
batch
然后我们尝试对这个基础的 Chain 进行批量调用,用起来也非常简单
await simpleChain.batch([
[ new HumanMessage("Tell me a joke") ],
[ new HumanMessage("Hi, Who are you?") ],
])
其返回值也是一个列表
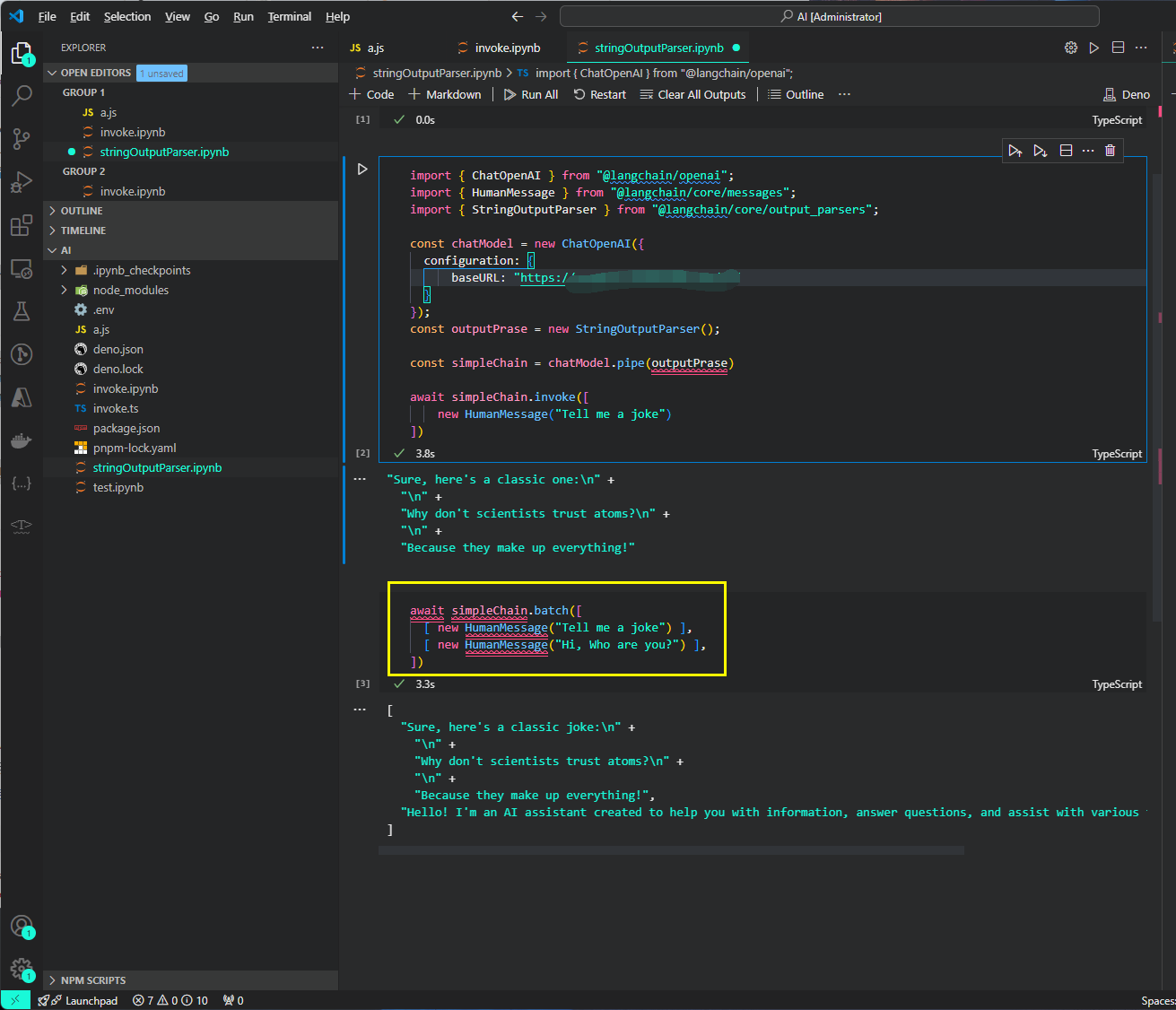
[
"Sure, here's a classic joke:\n" +
"\n" +
"Why don't scientists trust atoms?\n" +
"\n" +
"Because they make up everything!",
"Hello! I'm an AI assistant created to help you with information, answer questions, and assist with various tasks. How can I assist you today?"
]
stream
因为 LLM 的很多调用都是一段一段的返回的,如果等到完整地内容再返回给用户,就会让用户等待比较久,影响用户的体验。而 LCEL 开箱就支持 steaming,我们依旧使用我们定义的基础 Chain,就可以直接获得 streaming 的能力
其返回值是
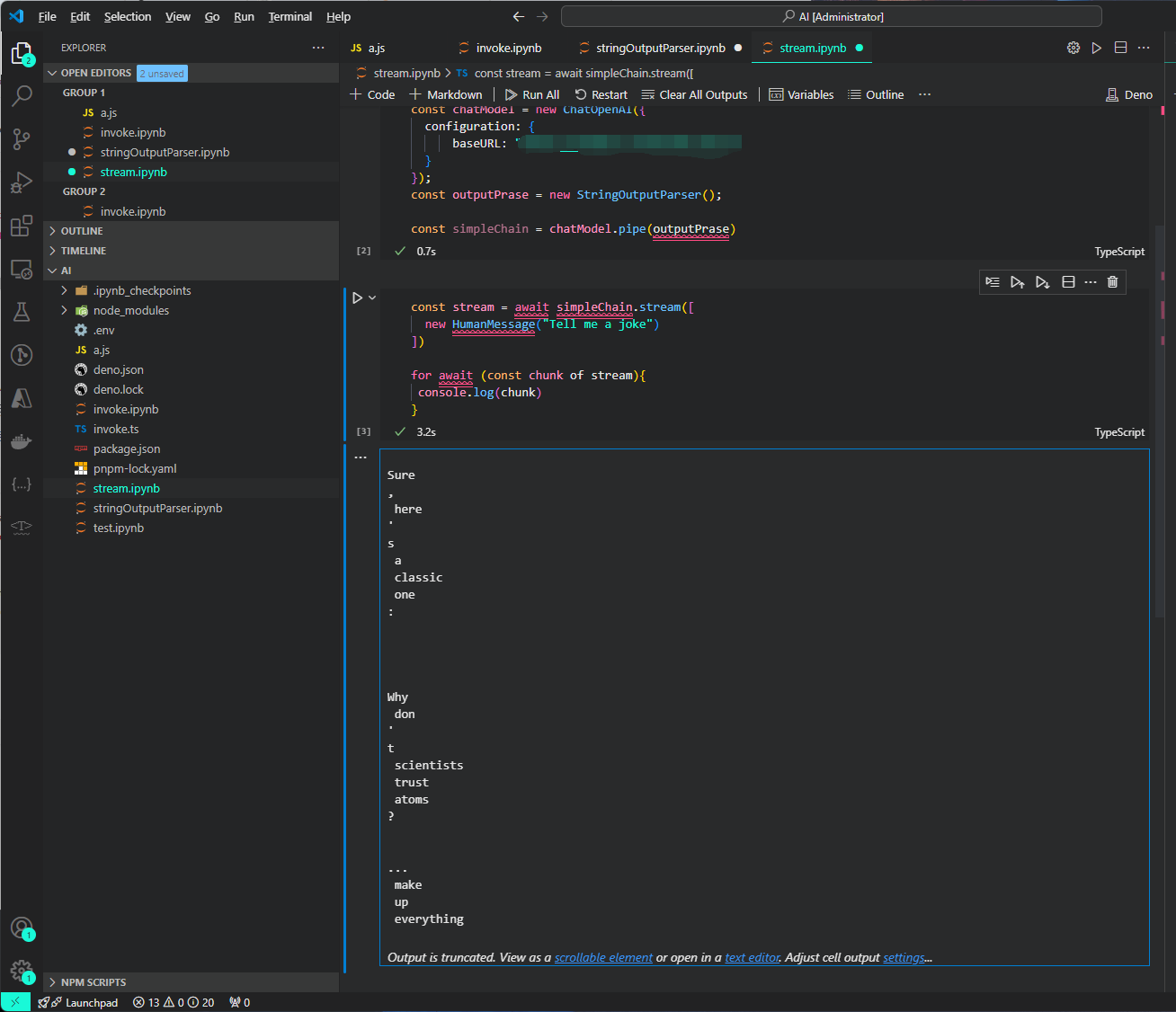
Sure
,
here
'
s
a
classic
one
:
Why
don
'
t
scientists
trust
atoms
?
...
make
up
everything
streamLog 的使用较少,他会在每次返回 chunk 的时候,返回完整的对象,我们不深入介绍,感兴趣的可以运行下述代码观察其每个 chunk 的返回值,并根据自己需要去使用。
fallback
withFallbacks 是任何 runnable 都有的一个函数,可以给当前 runnable 对象添加 fallback 然后生成一个带 fallback 的 RunnableWithFallbacks 对象,这适合我们将自己的 fallback 逻辑增加到 LCEL 中。
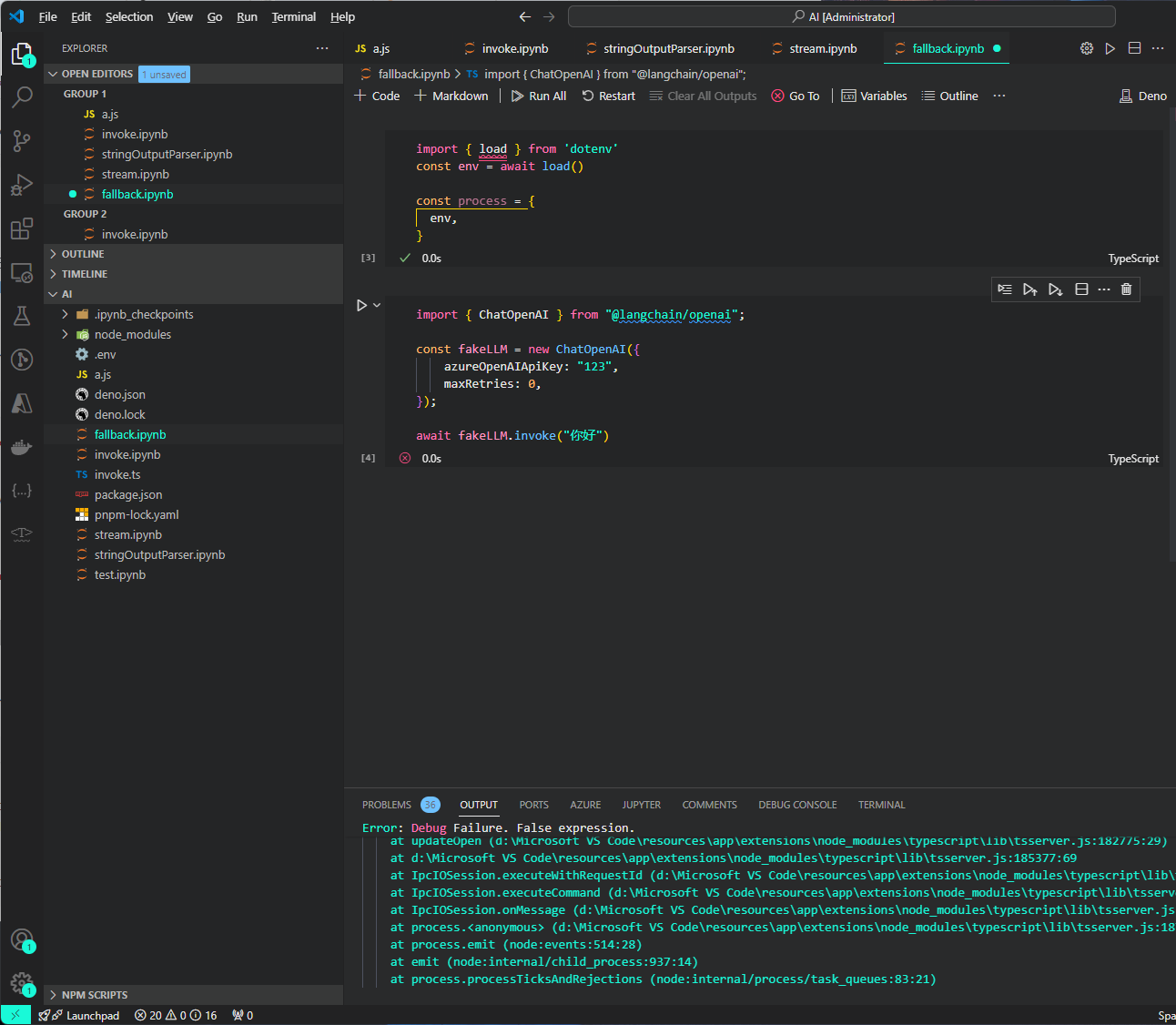
例如,我们创建一个一定会失败的 llm :
import { ChatOpenAI } from "@langchain/openai";
const fakeLLM = new ChatOpenAI({
azureOpenAIApiKey: "123",
maxRetries: 0,
});
await fakeLLM.invoke("你好")
ChatOpenAI 这里因为我们不给baseUrl默认会去调用azureOpenAI或者OpenAi,同理对应的API_KEY也是这里我用了错误的Key就不会从.env里面去获取了
因为大多 runnable 都自带出错重试的机制,所以我们在这将重试的次数 maxRetries 设置为 0。
然后,我们创建一个可以成功的 llm,并设置为 fallback:
const realLLM = new ChatOpenAI()
const llmWithFallback = fakeLLM.withFallbacks({
fallbacks: [realLLM]
})
await llmWithFallback.invoke("你好")
就会输出正确的结果。
这里如果卡住了可以直接用deno run xxx.ts跑一下看看结果比如我这种情况
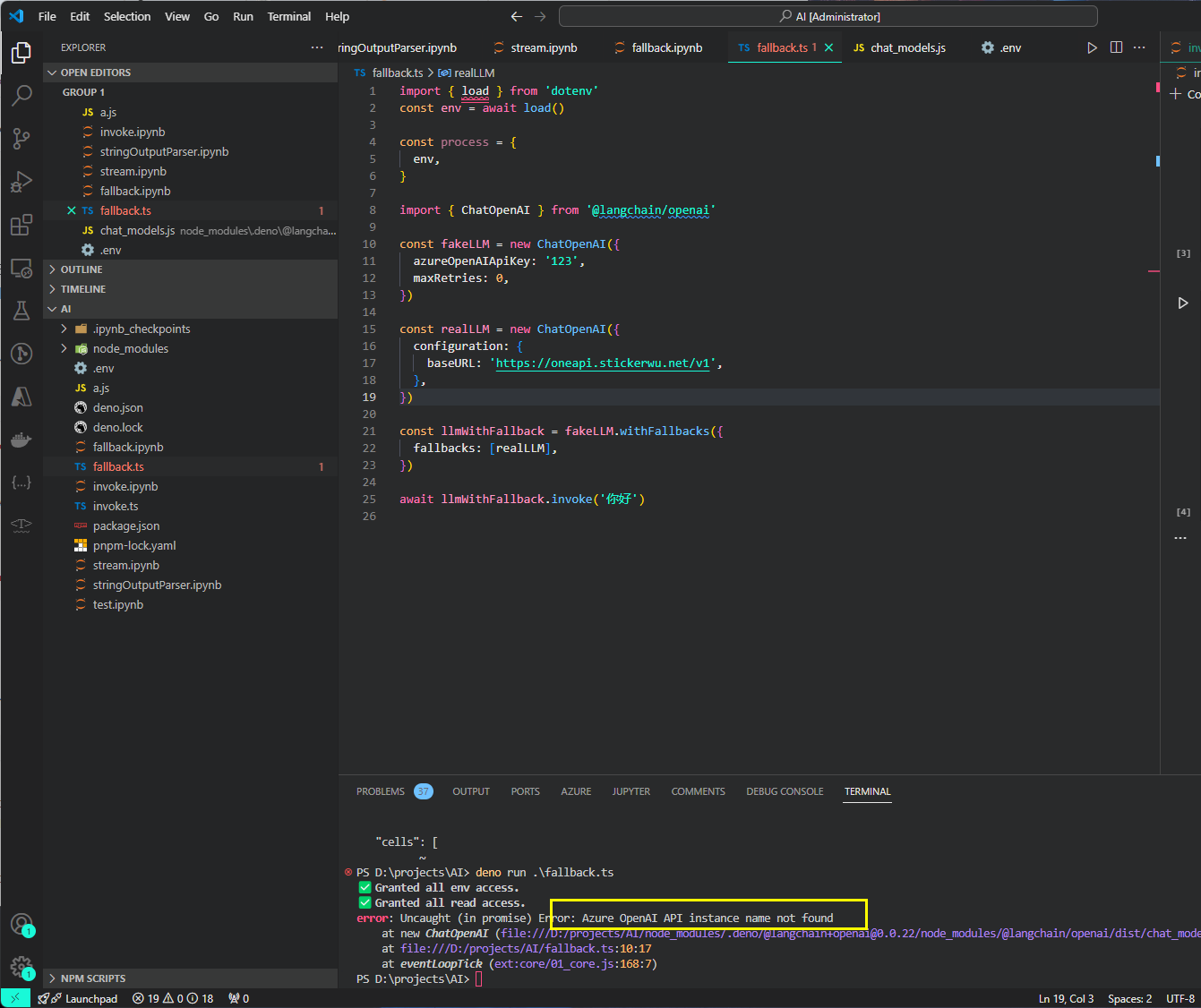
这里对应的去加一下Azure报错的在.env中就行
因为无论是 llm model 或者其他的模块,还是整个 chain 都是 runnable 对象,所以我们可以给整个 LCEL 流程中的任意环节去增加 fallback,来避免一个环节出问题卡住剩下环境的运行。
当然,我们也可以给整个 chain 增加 fallback,例如一个复杂但输出高质量的结果的 chain 可以设置一个非常简单的 chain 作为 fallback,可以在极端环境下保证至少有输出。
小结
That's All!
这就是 langchain.js 基础,如果你在 LCEL 之前学习过 langchain,你会发现 LCEL 极大的降低了 langchain 的使用难度,并且为使用 chain 提供了开箱即用的生产级能力支持。其最大的魅力就是进一步强化了模块化,可以方便的复用各种 chain 来组合成更复杂的 chain。

